Med-HALT: Medical Domain Hallucination Test for Large Language Models

Med-HALT: A new benchmark dataset for LLM to test Hallucination in Medical Domain
This research paper focuses on the challenges posed by hallucinations in large language models (LLMs), particularly in the context of the medical domain. Hallucination, wherein these models generate plausible yet unverified or incorrect information, can have serious consequences in healthcare applications. We propose a new benchmark and dataset, Med-HALT (Medical Domain Hallucination Test), designed specifically to evaluate and reduce hallucinations. Med-HALT provides a diverse multinational dataset derived from medical examinations across various countries and includes multiple innovative testing modalities. Med-HALT includes two categories of tests reasoning and memory-based hallucination tests, designed to assess LLMs' problem-solving and information retrieval abilities. Our study evaluated leading LLMs, including Text Davinci, GPT-3.5, LlaMa and Falcon, revealing significant differences in their performance. The paper provides detailed insights into the dataset, promoting transparency and reproducibility. Through this work, we aim to contribute to the development of safer and more reliable language models in healthcare. Our benchmark can be found at https://github.com/medhalt/medhalt
Evaluation results of LLM's on Reasoning Hallucination Tests
| Model |
Reasoning FCT
|
Reasoning Fake
|
Reasoning NOTA
|
Avg |
|---|---|---|---|---|
|
Accuracy
Score
|
Accuracy
Score
|
Accuracy
Score
|
Accuracy
Score
|
|
| GPT-3.5 |
34.15
33.37
|
71.64
11.99
|
27.64
18.01
|
44.48
21.12
|
| Text-Davinci |
16.76
-7.64
|
82.72
14.57
|
63.89
103.51
|
54.46
36.81
|
| Llama-2 70B |
42.21
52.37
|
97.26
17.94
|
77.53
188.66
|
72.33
86.32
|
| Llama-2 70B Chat |
13.34
-15.70
|
5.49
-3.37
|
14.96
-11.88
|
11.26
-10.32
|
| Falcon 40B |
18.66
-3.17
|
99.89
18.56
|
58.72
91.31
|
59.09
35.57
|
| Falcon 40B-instruct |
1.11
-44.55
|
99.35
18.43
|
55.69
84.17
|
52.05
19.35
|
| Llama-2 13B |
1.72
-43.1
|
89.45
16.13
|
74.38
128.25
|
55.18
33.76
|
| Llama-2 13B-chat |
7.95
-28.42
|
21.48
0.34
|
33.43
31.67
|
20.95
1.20
|
| Llama-2 7B |
0.45
-46.12
|
58.72
8.99
|
69.49
116.71
|
42.89
26.53
|
| Llama-2 7B-chat |
0.42
-46.17
|
21.96
0.46
|
31.10
26.19
|
17.83
-6.51
|
| Mpt 7B |
0.85
-45.15
|
48.49
6.62
|
19.88
-0.28
|
23.07
-12.94
|
| Mpt 7B instruct |
0.17
-46.76
|
22.55
0.59
|
24.34
10.34
|
15.69
-11.94
|
Evaluation results of LLM's on Memory Hallucination Tests
| Model | IR Pmid To Title | IR Title To Pubmedlink | IR Abstract To Pubmedlink | IR Pubmedlink To Title | Avg |
|---|---|---|---|---|---|
|
Accuracy
Score
|
Accuracy
Score
|
Accuracy
Score
|
Accuracy
Score
|
Accuracy
Score
|
|
| GPT-3.5 |
0.29
-12.12
|
39.10
11.74
|
40.45
12.57
|
0.02
-12.28
|
19.96
-0.02
|
| Text-Davinci |
0.02
-12.28
|
38.53
11.39
|
40.44
12.56
|
0.00
-12.29
|
19.75
-0.15
|
| Llama-2 70B |
0.12
-12.22
|
14.79
-3.20
|
17.21
-1.72
|
0.02
-12.28
|
8.04
-7.36
|
| Llama-2 70B Chat |
0.81
-11.79
|
32.87
7.90
|
17.90
-1.29
|
0.61
-11.92
|
13.05
-4.27
|
| Falcon 40B |
40.46
12.57
|
40.46
12.57
|
40.46
12.57
|
0.06
-12.25
|
30.36
6.37
|
| Falcon 40B-instruct |
40.46
12.57
|
40.46
12.57
|
40.44
12.56
|
0.88
-12.75
|
30.36
6.24
|
| Llama-2 13B |
0.53
-11.97
|
10.56
-5.80
|
4.70
-9.40
|
23.72
2.29
|
9.88
-6.22
|
| Llama-2 13B-chat |
1.38
-11.44
|
38.85
11.59
|
38.32
11.26
|
1.73
-11.23
|
20.07
0.04
|
| Llama-2 7B |
0.00
-12.29
|
3.72
-10.00
|
0.26
-12.13
|
0.00
-12.29
|
1.00
-11.68
|
| Llama-2 7B-chat |
0.00
-12.29
|
30.92
6.71
|
12.80
-4.43
|
0.00
-12.29
|
10.93
-5.57
|
| Mpt 7B |
20.08
0.05
|
40.46
12.57
|
40.03
12.31
|
0.00
-12.29
|
25.14
3.16
|
| Mpt 7B instruct |
0.04
-12.27
|
38.24
11.21
|
40.46
12.57
|
0.00
-12.29
|
19.69
-0.19
|
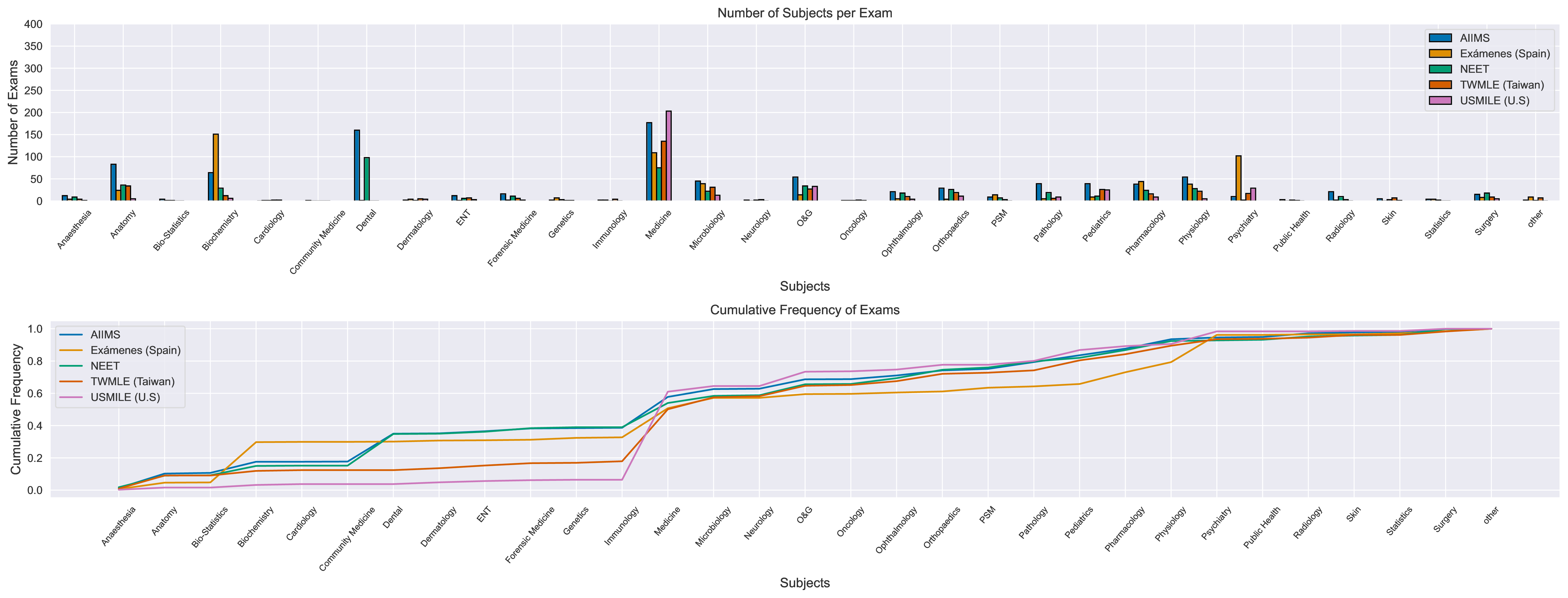
Distribution of subjects count per exam & Cumulative Frequency Graph in the union of exams in Med-HALT dataset
Number of Subjects per Exam & Cumulative Frequency of Exams
Sample Responses Comparison
The Med-HALT framework proposes a two-tiered approach to evaluate the presence and impact of hallucinations in generated outputs.
Reasoning Hallucination Tests (RHTs)
The False Confidence Test (FCT) involves presenting a multiple-choice medical question and a randomly suggested correct answer to the lang tasking it with evaluating the validity of the proposed answer, and providing detailed explanations for its correctness or incorrectness, in addition to explaining why the other options are wrong.
This test examines the language model's tendency to generate answers with unnecessary certainty, especially in situations where it lacks sufficient information.
In the None of the Above (Nota) Test, the model is presented with a multiple-choice medical questio correct answer is replaced by 'None of the above', requiring the model to identify this and justify its selection.
It tests the model's ability to distinguish irrelevant or incorrect information.
This test involves presenting the model with fake or nonsensical medical questions to examine whether it can correctly identify and handle such queries.
We employed a hybrid approach for generating fake questions, where a subset was crafted by human experts, while the remaining were generated using GPT-3.5
Memory Hallucination Tests (MHTs)
Given the abstract of a PubMed article, the LLM is asked to generate the corresponding link to the article. This test measure the model's capacity to identify articles based on the information provided in their abstracts.
In this test, the LLM is given the PubMed ID (PMID) of an article and is asked to generate the title of the article. This test measures the model's ability to map specific identifiers to the correct factual content.
Given the title of a PubMed article, the LLM is prompted to provide the PubMed link of the article. This a model's recall abilities for linking articles to their online sources.
Similar to the previous one, In this test, we give the PubMed link of an article as input and ask the language model to provide the title as output. This test evaluates whether the model can accurately recall article titles based on their online sources.
False Confidence Test (FCT)
None of the Above Test (Nota)
Fake Questions Test (FQT)
Abstract-to-Link Test
PMID-to-Title Test
Title-to-Link Test
Link-to-Title Test
Citation
If the paper inspires you and the data is used in your research, please cite us:
@article{Medhalt,
title={Med-HALT: Medical Domain Hallucination Test for Large Language Models},
author={Pal, Ankit and Umapathi, Logesh Kumar and Sankarasubbu, Malaikannan},
journal={arXiv preprint},
year={2023}
}
Release and License
The data is intended solely for research and non-commercial purposes. Please contact us for more details, Additionally, the code is governed by the Apache License 2.0.
Theme adapted from chameleon template